With all the hype around machine learning, I occasionally get asked if it could be used to make predictions for particle colliders, like the LHC.
Physicists do use machine learning these days, to be clear. There are tricks and heuristics, ways to quickly classify different particle collisions and speed up computation. But if you’re imagining something that replaces particle physics calculations entirely, or even replace the LHC itself, then you’re misunderstanding what particle physics calculations are for.
Why do physicists try to predict the results of particle collisions? Why not just observe what happens?
Physicists make predictions not in order to know what will happen in advance, but to compare those predictions to experimental results. If the predictions match the experiments, that supports existing theories like the Standard Model. If they don’t, then a new theory might be needed.
Those predictions certainly don’t need to be made by humans: most of the calculations are done by computers anyway. And they don’t need to be perfectly accurate: in particle physics, every calculation is an approximation. But the approximations used in particle physics are controlled approximations. Physicists keep track of what assumptions they make, and how they might go wrong. That’s not something you can typically do in machine learning, where you might train a neural network with millions of parameters. The whole point is to be able to check experiments against a known theory, and we can’t do that if we don’t know whether our calculation actually respects the theory.
That difference, between caring about the result and caring about how you got there, is a useful guide. If you want to predict how a protein folds in order to understand what it does in a cell, then you will find AlphaFold useful. If you want to confirm your theory of how protein folding happens, it will be less useful.
Some industries just want the final result, and can benefit from machine learning. If you want to know what your customers will buy, or which suppliers are cheating you, or whether your warehouse is moldy, then machine learning can be really helpful.
Other industries are trying, like particle physicists, to confirm that a theory is true. If you’re running a clinical trial, you want to be crystal clear about how the trial data turn into statistics. You, and the regulators, care about how you got there, not just about what answer you got. The same can be true for banks: if laws tell you you aren’t allowed to discriminate against certain kinds of customers for loans, you need to use a method where you know what traits you’re actually discriminating against.
So will physicists use machine learning? Yes, and more of it over time. But will they use it to replace normal calculations, or replace the LHC? No, that would be missing the point.
I posted a link last week to a dialogue written by a former colleague of mine, Sylvain Ribault. Sylvain’s dialogue is a summary of different perspectives on academic publishing. Unlike certain more famous dialogues written by physicists, Sylvain’s account doesn’t have a clear bias: he’s trying to set out the concerns different stakeholders might have and highlight the history of the subject, without endorsing one particular approach as the right one.
The purpose of such a dialogue is to provoke thought, and true to its purpose, the dialogue got me thinking.
Why do peer review? Why do we ask three or so people to read every paper, comment on it, and decide whether it should be published? While one can list many reasons, they seem to fall into two broad groups:
We want to distinguish better science from worse science. We want to reward the better scientists with jobs and grants and tenure. To measure whether scientists are better, we want to see whether they publish more often in the better journals. We then apply those measures on up the chain, funding universities more when they have better scientists, and supporting grant programs that bring about better science.
We want published science to be true. We want to make sure that when a paper is published that the result is actually genuine, free both from deception and from mistakes. We want journalists and the public to know which scientific results are valid, and we want scientists to know what results they can base their own research on.
The first set of goals is a product of scarcity. If we could pay every scientist and fund every scientific project with no cost, we wouldn’t need to worry so much about better and worse science. We’d fund it all and see what happens. The second set of goals is more universal: the whole point of science is to find out the truth, and we want a process that helps to achieve that.
My approach to science is to break problems down. What happens if we had only the second set of concerns, and not the first?
Well, what happens to hobbyists?
I’ve called hobby communities a kind of “post-scarcity academia”. Hobbyists aren’t trying to get jobs doing their hobby or get grants to fund it. They have their day jobs, and research their hobby as a pure passion project. There isn’t much need to rank which hobbyists are “better” than others, but they typically do care about whether what they write is true. So what happens when it’s not?
Sometimes, not much.
My main hobby community was Dungeons and Dragons. In a game with over 50 optional rulebooks covering multiple partially compatible-editions, there were frequent arguments about what the rules actually meant. Some were truly matters of opinion, but some were true misunderstandings, situations where many people thought a rule worked a certain way until they heard the right explanation.
One such rule regarded a certain type of creature called a Warbeast. Warbeasts, like Tolkien’s Oliphaunts, are “upgraded” versions of more normal wild animals, bred and trained for war. There were rules to train a Warbeast, and people interpreted these rules differently: some thought you could find an animal in the wild and train it to become a Warbeast, others thought the rules were for training a creature that was already a Warbeast to fight.
I supported the second interpretation: you can train an existing Warbeast, you can’t train a wild animal to make it into a Warbeast. As such, keep in mind, I’m biased. But every time I explained the reasoning (pointing out that the text was written in the context of an earlier version of the game, and how the numbers in it matched up with that version), people usually agreed with me. And yet, I kept seeing people use the other interpretation. New players would come in asking how to play the game, and get advised to go train wild animals to make them into Warbeasts.
Ok, so suppose the Dungeons and Dragons community had a peer review process. Would that change anything?
Not really! The wrong interpretation was popular. If whoever first proposed it got three random referees, there’s a decent chance none of them would spot the problem. In good science, sometimes the problems with an idea are quite subtle. Referees will spot obvious issues (and not even all of those!), but only the most diligent review (which sometimes happens in mathematics, and pretty much nowhere else) can spot subtle flaws in an argument. For an experiment, you sometimes need more than that: not just a review, but an actual replication.
What would have helped the Dungeons and Dragons community? Not peer review, but citations.
Suppose that, every time someone suggested you could train a wild animal to make it a Warbeast, they had to link to the first post suggesting you could do this. Then I could go to that first post, and try to convince the author that my interpretation was correct. If I succeeded, the author could correct their post, and then every time someone followed one of these citation links it would tell them the claim was wrong.
Academic citations don’t quite work like this. But the idea is out there. People have suggested letting anyone who wants to review a paper, and publishing the reviews next to the piece like comments on a blog post. Sylvain’s dialogue mentions a setup like this, and some of the risks involved.
Still, a setup like that would have gone a long way towards solving the problem for the Dungeons and Dragons community. It has me thinking that something like that is worth exploring.
Before this week’s post: a former colleague of mine from CEA Paris-Saclay, Sylvain Ribault, posted a dialogue last week presenting different perspectives on academic publishing. One of the highlights of my brief time at the CEA were the times I got to chat with Sylvain and others about the future forms academia might take. He showed me a draft of his dialogue a while ago, designed as a way to introduce newcomers to the debate about how, and whether, academics should do peer review. I’ve got a different topic this week so I won’t say much more about it, but I encourage you to take a look!
Matt Strassler has a nice post up about waves and particles. He’s writing to address a common confusion, between two concepts that sound very similar. On the other hand, there are the waves of quantum field theory, ripples in fundamental fields the smallest versions of which correspond to particles. (Strassler likes to call them “wavicles”, to emphasize their wavy role.) On the other hand, there are the wavefunctions of quantum mechanics, descriptions of the behavior of one or more interacting particles over time. To distinguish, he points out that wavicles can hurt you, while wavefunctions cannot. Wavicles are the things that collide and light up detectors, one by one, wavefunctions are the math that describes when and how that happens. Many types of wavicles can run into each other one by one, but their interactions can all be described together by a single wavefunction. It’s an important point, well stated.
After reading his post, there’s something that might still confuse you. You’ve probably heard that in quantum mechanics, an electron is both a wave and a particle. Does the “wave” in that saying mean “wavicle”, or “wavefunction”?
A “wave” built out of particles
The gif above shows data from a double-slit experiment, an important type of experiment from the early days of quantum mechanics. These experiments were first conducted before quantum field theory (and thus, before the ideas that Strassler summarizes with “wavicles”). In a double-slit experiment, particles are shot at a screen through two slits. The particles that hit the screen can travel through one slit or the other.
A double-slit experiment, in diagram form
Classically, you would expect particles shot randomly at the screen to form two piles on the other side, one in front of each slit. Instead, they bunch up into a rippling pattern, the same sort of pattern that was used a century earlier to argue that light was a wave. The peaks and troughs of the wave pass through both slits, and either line up or cancel out, leaving the distinctive pattern.
When it was discovered that electrons do this too, it led to the idea that electrons must be waves as well, despite also being particles. That insight led to the concept of the wavefunction. So the “wave” in the saying refers to wavefunctions.
But electrons can hurt you, and as Strassler points out, wavefunctions cannot. So how can the electron be a wavefunction?
To risk a bit of metaphysics myself, I’ll just say: it can’t. An electron can’t “be” a wavefunction.
The saying, that electrons are both particles and waves, is from the early days of quantum mechanics, when people were confused about what it all meant. We’re still confused, but we have some better ways to talk about it.
As a start, it’s worth noticing that, whenever you measure an electron, it’s a particle. Each electron that goes through the slits hits your screen as a particle, a single dot. If you see many electrons at once, you may get the feeling that they look like waves. But every actual electron you measure, every time you’re precise enough to notice, looks like a particle. And for each individual electron, you can extrapolate back the path it took, exactly as if it traveled like a particle the whole way through.
The same is true, though, of light! When you see light, photons enter your eyes, and each one that you see triggers a chemical change in a molecule called a photopigment. The same sort of thing happens for photographs, while an electrical signal gets triggered instead in a digital camera. Light may behave like a wave in some sense, but every time you actually observe it it looks like a particle.
But while you can model each individual electron, or photon, as a classical particle, you can’t model the distribution of multiple electrons that way.
That’s because in quantum mechanics, the “paths not taken” matter. A single electron will only go through one slit in the double-slit experiment. But the fact that it could have gone through both slits matters, and changes the chance that it goes through each particular path. The possible paths in the wavefunction interfere with each other, the same way different parts of classical waves do.
That role of the paths not taken, of the “what if”, is the heart and soul of quantum mechanics. No matter how you interpret its mysteries, “what if” matters. If you believe in a quantum multiverse, you think every “what if” happens somewhere in that infinity of worlds. If you think all that matters is observations, then “what if” shows the folly of modeling the world as anything else. If you are tempted to try to mend quantum mechanics with faster-than-light signals, then you have to declare one “what if” the true one. And if you want to double-down on determinism and replace quantum mechanics, you need to declare that certain “what if” questions are off-limits.
“What if matters” isn’t the same as a particle traveling every path at once, it’s its own weird thing with its own specific weird consequences. It’s a metaphor, because everything written in words is a metaphor. But it’s a better metaphor than thinking an electron is both a particle and a wave.
When investors put money in a company, they have some control over what that company does. They vote to decide a board, and the board votes to hire a CEO. If the company isn’t doing what the investors want, the board can fire the CEO, or the investors can vote in a new board. Everybody is incentivized to do what the people who gave the money want to happen. And usually, those people want the company to increase its profits, since most of them people are companies with their own investors).
Academics are paid by universities and research centers, funded in the aggregate by governments and student tuition and endowments from donors. But individually, they’re also often funded by grants.
What grant-givers want is more ambiguous. The money comes in big lumps from governments and private foundations, which generally want something vague like “scientific progress”. The actual decision of who gets the money are made by committees made up of senior scientists. These people aren’t experts in every topic, so they have to extrapolate, much as investors have to guess whether a new company will be profitable based on past experience. At their best, they use their deep familiarity with scientific research to judge which projects are most likely to work, and which have the most interesting payoffs. At their weakest, though, they stick with ideas they’ve heard of, things they know work because they’ve seen them work before. That, in a nutshell, is why mainstream research prevails: not because the mainstream wants to suppress alternatives, but because sometimes the only way to guess if something will work is raw familiarity.
(What “works” means is another question. The cynical answers are “publishes papers” or “gets citations”, but that’s a bit unfair: in Europe and the US, most funders know that these numbers don’t tell the whole story. The trivial answer is “achieves what you said it would”, but that can’t be the whole story, because some goals are more pointless than others. You might want the answer to be “benefits humanity”, but that’s almost impossible to judge. So in the end the answer is “sounds like good science”, which is vulnerable to all the fads you can imagine…but is pretty much our only option, regardless.)
So are academics incentivized to do what the grant committees want? Sort of.
Science never goes according to plan. Grant committees are made up of scientists, so they know that. So while many grants have a review process afterwards to see whether you achieved what you planned, they aren’t all that picky about it. If you can tell a good story, you can explain why you moved away from your original proposal. You can say the original idea inspired a new direction, or that it became clear that a new approach was necessary. I’ve done this with an EU grant, and they were fine with it.
Looking at this, you might imagine that an academic who’s a half-capable storyteller could get away with anything they wanted. Propose a fashionable project, work on what you actually care about, and tell a good story afterwards to avoid getting in trouble. As long as you’re not literally embezzling the money (the guy who was paying himself rent out of his visitor funding, for instance), what could go wrong? You get the money without the incentives, you move the scientific world and nobody gets to move you.
I can’t speak for Hossenfelder, but I’ve also put some thought into how to choose what to research, about whether I could actually be an unmoved mover. A few things get in the way:
First, applying for grants doesn’t just take storytelling skills, it takes scientific knowledge. Grant committees aren’t experts in everything, but they usually send grants to be reviewed by much more appropriate experts. These experts will check if your grant makes sense. In order to make the grant make sense, you have to know enough about the faddish topic to propose something reasonable. You have to keep up with the fad. You have to spend time reading papers, and talking to people in the faddish subfield. This takes work, but also changes your motivation. If you spend time around people excited by an idea, you’ll either get excited too, or be too drained by the dissonance to get any work done.
Second, you can’t change things that much. You still need a plausible story as to how you got from where you are to where you are going.
Third, you need to be a plausible person to do the work. If the committee looks at your CV and sees that you’ve never actually worked on the faddish topic, they’re more likely to give a grant to someone who’s actually worked on it.
Fourth, you have to choose what to do when you hire people. If you never hire any postdocs or students working on the faddish topic, then it will be very obvious that you aren’t trying to research it. If you do hire them, then you’ll be surrounded by people who actually care about the fad, and want your help to understand how to work with it.
Ultimately, to avoid the grant committee’s incentives, you need a golden tongue and a heart of stone, and even then you’ll need to spend some time working on something you think is pointless.
Even if you don’t apply for grants, even if you have a real permanent position or even tenure, you still feel some of these pressures. You’re still surrounded by people who care about particular things, by students and postdocs who need grants and jobs and fellow professors who are confident the mainstream is the right path forward. It takes a lot of strength, and sometimes cruelty, to avoid bowing to that.
So despite the ambiguous rules and lack of oversight, academics still respond to incentives: they can’t just do whatever they feel like. They aren’t bound by shareholders, they aren’t expected to make a profit. But ultimately, the things that do constrain them, expertise and cognitive load, social pressure and compassion for those they mentor, those can be even stronger.
I suspect that those pressures dominate the private sector as well. My guess is that for all that companies think of themselves as trying to maximize profits, the all-too-human motivations we share are more powerful than any corporate governance structure or org chart. But I don’t know yet. Likely, I’ll find out soon.
Peter Higgs, the theoretical physicist whose name graces the Higgs boson, died this week.
Peter Higgs, after the Higgs boson discovery was confirmed
This post isn’t an obituary: you can find plenty of those online, and I don’t have anything special to say that others haven’t. Reading the obituaries, you’ll notice they summarize Higgs’s contribution in different ways. Higgs was one of the people who proposed what today is known as the Higgs mechanism, the principle by which most (perhaps all) elementary particles gain their mass. He wasn’t the only one: Robert Brout and François Englert proposed essentially the same idea in a paper that was published two months earlier, in August 1964. Two other teams came up with the idea slightly later than that: Gerald Guralnik, Carl Richard Hagen, and Tom Kibble were published one month after Higgs, while Alexander Migdal and Alexander Polyakov found the idea independently in 1965 but couldn’t get it published till 1966.
Higgs did, however, do something that Brout and Englert didn’t. His paper doesn’t just propose a mechanism, involving a field which gives particles mass. It also proposes a particle one could discover as a result. Read the more detailed obituaries, and you’ll discover that this particle was not in the original paper: Higgs’s paper was rejected at first, and he added the discussion of the particle to make it more interesting.
At this point, I bet some of you are wondering what the big deal was. You’ve heard me say that particles are ripples in quantum fields. So shouldn’t we expect every field to have a particle?
Tell that to the other three Higgs bosons.
Electromagnetism has one type of charge, with two signs: plus, and minus. There are electrons, with negative charge, and their anti-particles, positrons, with positive charge.
Quarks have three types of charge, called colors: red, green, and blue. Each of these also has two “signs”: red and anti-red, green and anti-green, and blue and anti-blue. So for each type of quark (like an up quark), there are six different versions: red, green, and blue, and anti-quarks with anti-red, anti-green, and anti-blue.
Diagram of the colors of quarks
When we talk about quarks, we say that the force under which they are charged, the strong nuclear force, is an “SU(3)” force. The “S” and “U” there are shorthand for mathematical properties that are a bit too complicated to explain here, but the “(3)” is quite simple: it means there are three colors.
The Higgs boson’s primary role is to make the weak nuclear force weak, by making the particles that carry it from place to place massive. (That way, it takes too much energy for them to go anywhere, a feeling I think we can all relate to.) The weak nuclear force is an “SU(2)” force. So there should be two “colors” of particles that interact with the weak nuclear force…which includes Higgs bosons. For each, there should also be an anti-color, just like the quarks had anti-red, anti-green, and anti-blue. So we need two “colors” of Higgs bosons, and two “anti-colors”, for a total of four!
But the Higgs boson discovered at the LHC was a neutral particle. It didn’t have any electric charge, or any color. There was only one, not four. So what happened to the other three Higgs bosons?
The real answer is subtle, one of those physics things that’s tricky to concisely explain. But a partial answer is that they’re indistinguishable from the W and Z bosons.
Normally, the fundamental forces have transverse waves, with two polarizations. Light can wiggle along its path back and forth, or up and down, but it can’t wiggle forward and backward. A fundamental force with massive particles is different, because they can have longitudinal waves: they have an extra direction in which they can wiggle. There are two W bosons (plus and minus) and one Z boson, and they all get one more polarization when they become massive due to the Higgs.
That’s three new ways the W and Z bosons can wiggle. That’s the same number as the number of Higgs bosons that went away, and that’s no coincidence. We physicist like to say that the W and Z bosons “ate” the extra Higgs, which is evocative but may sound mysterious. Instead, you can think of it as the two wiggles being secretly the same, mixing together in a way that makes them impossible to tell apart.
The “count”, of how many wiggles exist, stays the same. You start with four Higgs wiggles, and two wiggles each for the precursors of the W+, W-, and Z bosons, giving ten. You end up with one Higgs wiggle, and three wiggles each for the W+, W-, and Z bosons, which still adds up to ten. But which fields match with which wiggles, and thus which particles we can detect, changes. It takes some thought to look at the whole system and figure out, for each field, what kind of particle you might find.
Higgs did that work. And now, we call it the Higgs boson.
They say when all you have is a hammer, everything looks like a nail.
Academics are a bit smarter than that. Confidently predict a world of nails, and you fall to the first paper that shows evidence of a screw. There are limits to how long you can delude yourself when your job is supposed to be all about finding the truth.
You can make your own nails, though.
Suppose there’s something you’re really good at. Maybe, like many of my past colleagues, you can do particle physics calculations faster than anyone else, even when the particles are super-complicated hypothetical gravitons. Maybe you know more than anyone else about how to make a quantum computer, or maybe you just know how to build a “quantum computer“. Maybe you’re an expert in esoteric mathematics, who can re-phrase anything in terms of the arcane language of category theory.
That’s your hammer. Get good enough with it, and anyone with a nail-based problem will come to you to solve it. If nails are trendy, then you’ll impress grant committees and hiring committees, and your students will too.
When nails aren’t trendy, though, you need to try something else. If your job is secure, and you don’t have students with their own insecure jobs banging down your door, then you could spend a while retraining. You could form a reading group, pick up a textbook or two about screwdrivers and wrenches, and learn how to use different tools. Eventually, you might find a screwdriving task you have an advantage with, something you can once again do better than everyone else, and you’ll start getting all those rewards again.
Or, maybe you won’t. You’ll get less funding to hire people, so you’ll do less research, so your work will get less impressive and you’ll get less funding, and so on and so forth.
Instead of risking that, most academics take another path. They take what they’re good at, and invent new problems in the new trendy area to use that expertise.
If everyone is excited about gravitational waves, you turn a black hole calculation into a graviton calculation. If companies are investing in computation in the here-and-now, then you find ways those companies can use insights from your quantum research. If everyone wants to know how AI works, you build a mathematical picture that sort of looks like one part of how AI works, and do category theory to it.
At first, you won’t be competitive. Your hammer isn’t going to work nearly as well as the screwdrivers people have been using forever for these problems, and there will be all sorts of new issues you have to solve just to get your hammer in position in the first place. But that doesn’t matter so much, as long as you’re honest. Academic research is expected to take time, applications aren’t supposed to be obvious. Grant committees care about what you’re trying to do, as long as you have a reasonably plausible story about how you’ll get there.
(Investors are also not immune to a nice story. Customers are also not immune to a nice story. You can take this farther than you might think.)
So, unlike the re-trainers, you survive. And some of the time, you make it work. Your hammer-based screwdriving ends up morphing into something that, some of the time, actually does something the screwdrivers can’t. Instead of delusionally imagining nails, you’ve added a real ersatz nail to the world, where previously there was just a screw.
Making nails is a better path for you. Is it a better path for the world? I’m not sure.
If all those grants you won, all those jobs you and your students got, all that money from investors or customers drawn in by a good story, if that all went to the people who had the screwdrivers in the first place, could they have done a better job?
Sometimes, no. Sometimes you happen upon some real irreproducible magic. Your hammer is Thor’s hammer, and when hefted by the worthy it can do great things.
Sometimes, though, your hammer was just the hammer that got the funding. Now every screwdriver kit has to have a space for a little hammer, when it could have had another specialized screwdriver that fit better in the box.
In the end, the world is build out of these kinds of ill-fitting toolkits. We all try to survive, both as human beings and by our sub-culture’s concept of the good life. We each have our hammers, and regardless of whether the world is full of screws, we have to convince people they want a hammer anyway. Everything we do is built on a vast rickety pile of consequences, the end-results of billions of people desperate to be wanted. For those of us who love clean solutions and ideal paths, this is maddening and frustrating and terrifying. But it’s life, and in a world where we never know the ideal path, screw-nails and nail-screws are the best way we’ve found to get things done.
In physics and in machine learning, we have different ways of thinking about models.
A model in physics, like the Standard Model, is a tool to make predictions. Using statistics and a whole lot of data (from particle physics experiments), we fix the model’s free parameters (like the mass of the Higgs boson). The model then lets us predict what we’ll see next: when we turn on the Large Hadron Collider, what will the data look like? In physics, when a model works well, we think that model is true, that it describes the real way the world works. The Standard Model isn’t the ultimate truth: we expect that a better model exists that makes better predictions. But it is still true, in an in-between kind of way. There really are Higgs bosons, even if they’re a result of some more mysterious process underneath, just like there really are atoms, even if they’re made out of protons, neutrons, and electrons.
A model in machine learning, like the Large Language Model that fuels ChatGPT, is also a tool to make predictions. Using statistics and a whole lot of data (from text on the internet, or images, or databases of proteins, or games of chess…) we fix the model’s free parameters (called weights, numbers for the strengths of connections between metaphorical neurons). The model then lets us predict what we’ll see next: when a text begins “Q: How do I report a stolen card? A:”, how does it end?
So far, that sounds a lot like physics. But in machine learning, we don’t generally think these models are true, at least not in the same way. The thing producing language isn’t really a neural network like a Large Language Model. It’s the sum of many human brains, many internet users, spread over many different circumstances. Each brain might be sort of like a neural network, but they’re not like the neural networks sitting on OpenAI’s servers. A Large Language Model isn’t true in some in-between kind of way, like atoms or Higgs bosons. It just isn’t true. It’s a black box, a machine that makes predictions, and nothing more.
But here’s the rub: what do we mean by true?
I want to be a pragmatist here. I don’t want to get stuck in a philosophical rabbit-hole, arguing with metaphysicists about what “really exists”. A true theory should be one that makes good predictions, that lets each of us know, based on our actions, what we should expect to see. That’s why science leads to technology, why governments and companies pay people to do it: because the truth lets us know what will happen, and make better choices. So if Large Language Models and the Standard Model both make good predictions, why is only one of them true?
Recently, I saw Dan Elton of More is Different make the point that there is a practical reason to prefer the “true” explanations: they generalize. A Large Language Model might predict what words come next in a text. But it doesn’t predict what happens when you crack someone’s brain open and see how the neurons connect to each other, even if that person is the one who made the text. A good explanation, a true model, can be used elsewhere. The Standard Model tells you what data from the Large Hadron Collider will look like, but it also tells you what data from the muon g-2 experiment will look like. It also, in principle, tells you things far away from particle physics: what stars look like, what atoms look like, what the inside of a nuclear reactor looks like. A black box can’t do that, even if it makes great predictions.
It’s a good point. But thinking about it, I realized things are a little murkier.
You can’t generalize a Large Language Model to tell you how human neurons are connected. But you can generalize it in other ways, and people do. There’s a huge industry in trying to figure out what GPT and its relatives “know”. How much math can they do? How much do they know about geography? Can they predict the future?
These generalizations don’t work the way that they do in physics, or the rest of science, though. When we generalize the Standard Model, we aren’t taking a machine that makes particle physics predictions and trying to see what those particle physics predictions can tell us. We’re taking something “inside” the machine, the fields and particles, and generalizing that, seeing how the things around us could be made of those fields and those particles. In contrast, when people generalize GPT, they typically don’t look inside the “black box”. They use the Large Language Model to make predictions, and see what those predictions “know about”.
On the other hand, we do sometimes generalize scientific models that way too.
If you’re simulating the climate, or a baby star, or a colony of bacteria, you typically aren’t using your simulation like a prediction machine. You don’t plug in exactly what is going on in reality, then ask what happens next. Instead, you run many simulations with different conditions, and look for patterns. You see how a cloud of sulfur might cool down the Earth, or how baby stars often form in groups, leading them to grow up into systems of orbiting black holes. Your simulation is kind of like a black box, one that you try out in different ways until you uncover some explainable principle, something your simulation “knows” that you can generalize.
And isn’t nature that kind of black box, too? When we do an experiment, aren’t we just doing what the Large Language Models are doing, prompting the black box in different ways to get an idea of what it knows? Are scientists who do experiments that picky about finding out what’s “really going on”, or do they just want a model that works?
We want our models to be general, and to be usable. Building a black box can’t be the whole story, because a black box, by itself, isn’t general. But it can certainly be part of the story. Going from the black box of nature to the black box of a machine lets you run tests you couldn’t previously do, lets you investigate faster and ask stranger questions. With a simulation, you can blow up stars. With a Large Language Model, you can ask, for a million social media comments, whether the average internet user would call them positive or negative. And if you make sure to generalize, and try to make better decisions, then it won’t be just the machine learning. You’ll be learning too.
A commenter recently asked me about the different “tribes” in my sub-field. I’ve been working in an area called “amplitudeology”, where we try to find more efficient ways to make predictions (calculate “scattering amplitudes”) for particle physics and gravitational waves. I plan to do a longer post on the “tribes” of amplitudeology…but not this week.
This week, I’ve got a simpler goal. I want to talk about where these kinds of “tribes” come from, in general. A sub-field is a group of researchers focused on a particular idea, or a particular goal. How do those groups change over time? How do new sub-groups form? For the amplitudes fans in the audience, I’ll use amplitudeology examples to illustrate.
The first way subfields gain new tribes is by differentiation. Do a PhD or a Postdoc with someone in a subfield, and you’ll learn that subfield’s techniques. That’s valuable, but probably not enough to get you hired: if you’re just a copy of your advisor, then the field just needs your advisor: research doesn’t need to be done twice. You need to differentiate yourself, finding a variant of what your advisor does where you can excel. The most distinct such variants go on to form distinct tribes of their own. This can also happen for researchers at the same level who collaborate as Postdocs. Each has to show something new, beyond what they did as a team. In my sub-field, it’s the source of some of the bigger tribes. Lance Dixon, Zvi Bern, and David Kosower made their names working together, but when they found long-term positions they made new tribes of their own. Zvi Bern focused on supergravity, and later on gravitational waves, while Lance Dixon was a central figure in the symbology bootstrap.
(Of course, if you differentiate too far you end up in a different sub-field, or a different field altogether. Jared Kaplan was an amplitudeologist, but I wouldn’t call Anthropic an amplitudeology project, although it would help my job prospects if it was!)
The second way subfields gain new tribes is by bridges. Sometimes, a researcher in a sub-field needs to collaborate with someone outside of that sub-field. These collaborations can just be one-and-done, but sometimes they strike up a spark, and people in each sub-field start realizing they have a lot more in common than they realized. They start showing up to each other’s conferences, and eventually identifying as two tribes in a single sub-field. An example from amplitudeology is the group founded by Dirk Kreimer, with a long track record of interesting work on the boundary between math and physics. They didn’t start out interacting with the “amplitudeology” community itself, but over time they collaborated with them more and more, and now I think it’s fair to say they’re a central part of the sub-field.
A third way subfields gain new tribes is through newcomers. Sometimes, someone outside of a subfield will decide they have something to contribute. They’ll read up on the latest papers, learn the subfield’s techniques, and do something new with them: applying them to a new problem of their own interest, or applying their own methods to a problem in the subfield. Because these people bring something new, either in what they work on or how they do it, they often spin off new tribes. Many new tribes in amplitudeology have come from this process, from Edward Witten’s work on the twistor string bringing in twistor approaches to Nima Arkani-Hamed’s idiosyncratic goals and methods.
There are probably other ways subfields gain new tribes, but these are the ones I came up with. If you think of more, let me know in the comments!
Back in the Fall, I spent most of my time writing a grant proposal.
In Europe, getting a European Research Council (ERC) grant is how you know you’ve made it as a researcher. Covering both science and the humanities, ERC grants give a lump of funding big enough to hire a research group, turning you from a lone expert into a local big-shot. The grants last five years, and are organized by “academic age”, the number of years since your PhD. ERC Starting Grants give 1.5 million euros for those with academic age 2-7. At academic age 7-12, you need to apply for the Consolidator Grant. The competition is fiercer, but if you make it through you get 2 million euros. Finally, Advanced Grants give 2.5 million to more advanced researchers.
I’m old, at least in terms of academic age. I applied to the ERC Starting Grant in 2021, but this last year I was too academically old to qualify, so I applied to the Consolidator Grant instead.
I won’t know if they invite me for an interview until June…but since I’m leaving the field, there wouldn’t be much point in going anyway. So I figured, why not share the grant application with you guys?
That’s what I’m doing in this post. I think there are good ideas in here, a few research directions that fellow amplitudeologists might want to consider. (I’ve removed details on one of them, the second work package, because some friends of mine are already working on it.)
The format could also be helpful. My wife is more than a bit of a LaTeX wiz, she coded up Gantt charts and helped with the format of the headers and the color scheme. If you want an ERC proposal that doesn’t look like the default thing you could do with LaTeX or Word, then take a look.
Finally, I suspect some laymen in the audience are just curious what a scientific grant proposal looks like. While I’ve cut a few things (and a few of these were shorter than they ought to have been to begin with), this might satisfy your curiosity.
On this blog, I write about particle physics for the general public. I try to make things as simple as possible, but I do have to assume some things. In particular, I usually assume you know what particles are!
This time, I won’t do that. I know some people out there don’t know what a particle is, or what particle physicists do. If you’re a person like that, this post is for you! I’m going to give a gentle introduction to what particle physics is all about.
Let’s start with atoms.
Every object and substance around you, everything you can touch or lift or walk on, the water you drink and the air you breathe, all of these are made up of atoms. Some are simple: an iron bar is made of Iron atoms, aluminum foil is mostly Aluminum atoms. Some are made of combinations of atoms into molecules, like water’s famous H2O: each molecule has two Hydrogen atoms and one Oxygen atom. Some are made of more complicated mixtures: air is mostly pairs of Nitrogen atoms, with a healthy amount of pairs of Oxygen, some Carbon Dioxide (CO2), and many other things, while the concrete sidewalks you walk on have Calcium, Silicon, Aluminum, Iron, and Oxygen, all combined in various ways.
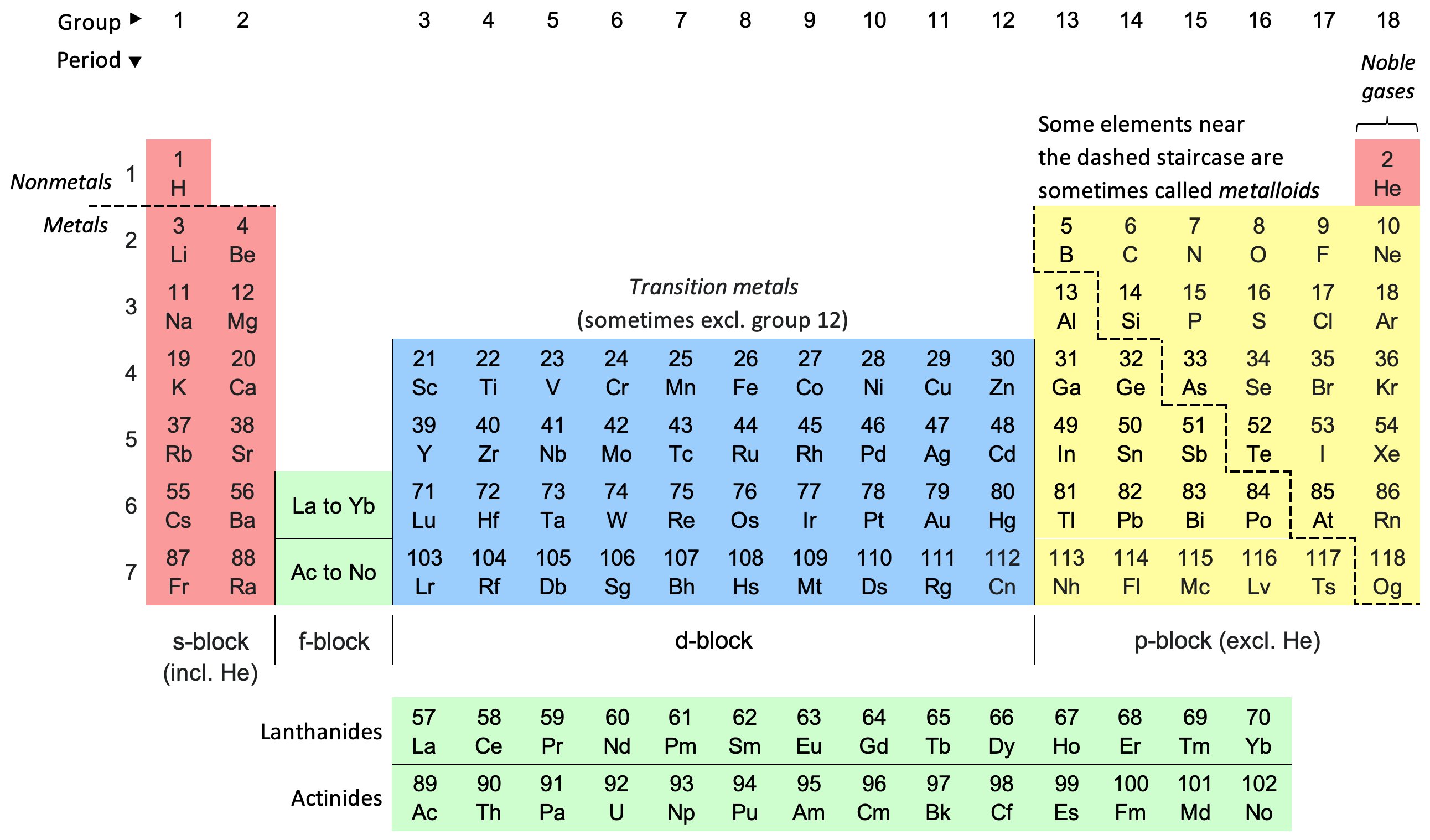
There is a dizzying array of different types of atoms, called chemical elements. Most occur in nature, but some are man-made, created by cutting-edge nuclear physics. They can all be organized in the periodic table of elements, which you’ve probably seen on a classroom wall.
The periodic table
The periodic table is called the periodic table because it repeats, periodically. Each element is different, but their properties resemble each other. Oxygen is a gas, Sulfur a yellow powder, Polonium an extremely radioactive metal…but just as you can find H2O, you can make H2S, and even H2Po. The elements get heavier as you go down the table, and more metal-like, but their chemical properties, the kinds of molecules you can make with them, repeat.
Around 1900, physicists started figuring out why the elements repeat. What they discovered is that each atom is made of smaller building-blocks, called sub-atomic particles. (“Sub-atomic” because they’re smaller than atoms!) Each atom has electrons on the outside, and on the inside has a nucleus made of protons and neutrons. Atoms of different elements have different numbers of protons and electrons, which explains their different properties.
Different atoms with different numbers of protons, neutrons, and electrons
Around the same time, other physicists studied electricity, magnetism, and light. These things aren’t made up of atoms, but it was discovered that they are all aspects of the same force, the electromagnetic force. And starting with Einstein, physicists figured out that this force has particles too. A beam of light is made up of another type of sub-atomic particle, called a photon.
For a little while then, it seemed that the universe was beautifully simple. All of matter was made of electrons, protons, and neutrons, while light was made of photons.
(There’s also gravity, of course. That’s more complicated, in this post I’ll leave it out.)
Soon, though, nuclear physicists started noticing stranger things. In the 1930’s, as they tried to understand the physics behind radioactivity and mapped out rays from outer space, they found particles that didn’t fit the recipe. Over the next forty years, theoretical physicists puzzled over their equations, while experimental physicists built machines to slam protons and electrons together, all trying to figure out how they work.
Finally, in the 1970’s, physicists had a theory they thought they could trust. They called this theory the Standard Model. It organized their discoveries, and gave them equations that could predict what future experiments would see.
In the Standard Model, there are two new forces, the weak nuclear force and the strong nuclear force. Just like photons for the electromagnetic force, each of these new forces has a particle. The general word for these particles is bosons, named after Satyendra Nath Bose, a collaborator of Einstein who figured out the right equations for this type of particle. The weak force has bosons called W and Z, while the strong force has bosons called gluons. A final type of boson, called the Higgs boson after a theorist who suggested it, rounds out the picture.
The Standard Model also has new types of matter particles. Neutrinos interact with the weak nuclear force, and are so light and hard to catch that they pass through nearly everything. Quarks are inside protons and neutrons: a proton contains one one down quark and two up quarks, while a neutron contains two down quarks and one up quark. The quarks explained all of the other strange particles found in nuclear physics.
Finally, the Standard Model, like the periodic table, repeats. There are three generations of particles. The first, with electrons, up quarks, down quarks, and one type of neutrino, show up in ordinary matter. The other generations are heavier, and not usually found in nature except in extreme conditions. The second generation has muons (similar to electrons), strange quarks, charm quarks, and a new type of neutrino called a muon-neutrino. The third generation has tauons, bottom quarks, top quarks, and tau-neutrinos.
(You can call these last quarks “truth quarks” and “beauty quarks” instead, if you like.)
Physicists had the equations, but the equations still had some unknowns. They didn’t know how heavy the new particles were, for example. Finding those unknowns took more experiments, over the next forty years. Finally, in 2012, the last unknown was found when a massive machine called the Large Hadron Collider was used to measure the Higgs boson.
The Standard Model
We think that these particles are all elementary particles. Unlike protons and neutrons, which are both made of up quarks and down quarks, we think that the particles of the Standard Model are not made up of anything else, that they really are elementary building-blocks of the universe.
We have the equations, and we’ve found all the unknowns, but there is still more to discover. We haven’t seen everything the Standard Model can do: to see some properties of the particles and check they match, we’d need a new machine, one even bigger than the Large Hadron Collider. We also know that the Standard Model is incomplete. There is at least one new particle, called dark matter, that can’t be any of the known particles. Mysteries involving the neutrinos imply another type of unknown particle. We’re also missing deeper things. There are patterns in the table, like the generations, that we can’t explain.
We don’t know if any one experiment will work, or if any one theory will prove true. So particle physicists keep working, trying to find new tricks and make new discoveries.